Is something bugging you?

It’s pretty weird for a startup to remain in stealth for over five years. People ask me why we did that, and my answer is always the same: “We wanted to build something awesome before releasing it out into the wild, and we were lucky enough to be able to do that under the radar while also attracting great hires, finding early customers, and working with investors.” All the same, it’s an unnatural thing for a startup to do. A lot of muscles end up atrophying, including those you use to talk to the world. Fortunately, we’re going to get a lot of practice at it now, because in those five years we’ve built a lot of stuff – way more than I can tell you about right now. But I can tell you the first part of it.
Why we built this
Some of you have heard of our last company, FoundationDB. At first glance, Antithesis couldn’t be more different from FoundationDB, but it’s also a continuation of that story in a funny sort of way. When we sat down in 2010 to build a scalable, fault-tolerant distributed database with ACID transactions, most people didn’t even think it was possible.1 We were agnostic as to whether it was possible or impossible, but we were certain that even under the best circumstances, it would be very hard. And the part that seemed hardest was how on earth you could test or validate such a thing, and how you could gain confidence in its correctness.
The fundamental problem of software testing—you might say the fundamental problem of software development—is that software has to handle many situations that the developer has never thought of or will never anticipate. This limits the value of testing, because if you had the foresight to write a test for a particular case, then you probably had the foresight to make the code handle that case too. This makes conventional testing great for catching regressions, but really terrible at catching all the “unknown unknowns” that life, the universe, and your endlessly creative users will throw at you.

This isn’t unique to distributed databases: every kind of software has this problem, but a distributed storage system really turns it up to 11. Now you’ve got concurrency, both within each machine and between machines. You’ve got networks, which always seem to be delaying or reordering packets at the worst possible moments, and disks, which are just waiting for you to look away so they can start vomiting all over your data. And then you’ve got all the stuff that can really go wrong—machine failures and power outages and datacenters catching fire and, oh yeah, well-meaning human beings panicking and accidentally making things worse. What’s especially hard about these failure modes is that they’re non-deterministic—you can easily have a catastrophic bug that’s exquisitely dependent on the precise ordering of events across multiple machines in a cluster. Even if your tests find it once, they may never find it again (but don’t worry, your customers will find it for you). And here we were, trying to make a software system that would behave perfectly and maintain its ACID guarantees in the face of all of this. How were we going to do that?
So we did something crazy, which turned out to be the best decision we made in the whole history of the company. Before we even started writing the database, we first wrote a fully-deterministic event-based network simulation that our database could plug into. This system let us simulate an entire cluster of interacting database processes, all within a single-threaded, single-process application, and all driven by the same random number generator. We could run this virtual cluster, inject network faults, kill machines, simulate whatever crazy behavior we wanted, and see how it reacted. Best of all, if one particular simulation run found a bug in our application logic, we could run it over and over again with the same random seed, and the exact same series of events would happen in the exact same order. That meant that even for the weirdest and rarest bugs, we got infinity “tries” at figuring it out, and could add logging, or do whatever else we needed to do to track it down. I gave a talk about this at Strangeloop in 2014, which you can watch here.
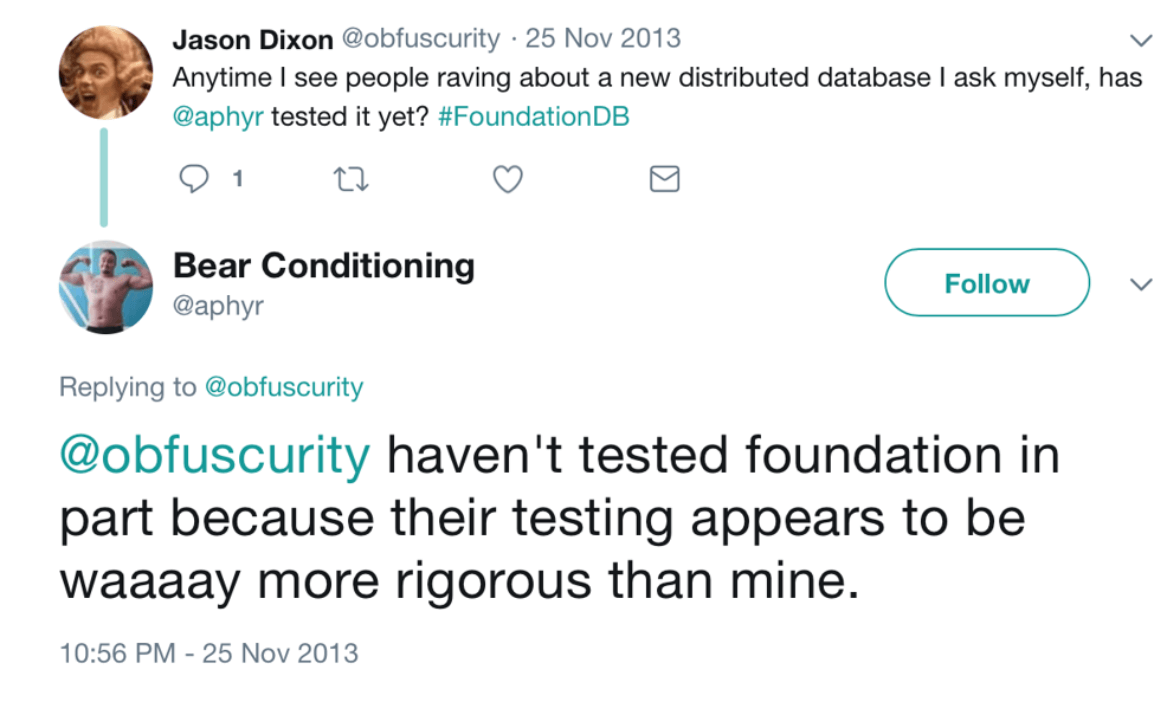
Anyway, we did this for a while and found all of the bugs in the database. I know, I know, that’s an insane thing to say. It’s kind of true though. In the entire history of the company, I think we only ever had one or two bugs reported by a customer. Ever. Kyle Kingsbury aka “aphyr” didn’t even bother testing it with Jepsen, because he didn’t think he’d find anything.
It was a good database. But actually, this is not the cool part of the story.
Here is the cool part of the story. The cool part is what happened after we found all the bugs in the database. You see, once you’ve found all the bugs in something, and you have very powerful tests which can find any new ones, programming feels completely different. I’ve only gotten to do this a few times in my career, and it’s hard to convey the feeling in words, but I have to try. It’s like being half of a cyborg, or having a jetpack, or something. You write code, and then you ask the computer if the code is correct, and if not then you try again. Can you imagine having a genie, or an oracle, which just tells you whether you did something wrong? The closest comparison I have is the way some people talk about programming in Haskell or in Rust, where after half an hour of siege warfare against the compiler, it agrees to build something, and you can be confident that it won’t have certain kinds of bugs. But there’s a limit to what a compiler can tell you. I love me a powerful type system, but it’s not the same as actually running your software in thousands and thousands of crazy situations you’d never dreamed of.
At FoundationDB, once we hit the point of having ~zero bugs and confidence that any new ones would be found immediately, we entered into this blessed condition and we flew. Programming in this state is like living life surrounded by a force field that protects you from all harm. Suddenly, you feel like you can take risks. We did crazy stuff. We deleted all of our dependencies (including Zookeeper) because they had bugs, and wrote our own Paxos implementation in very little time and it had no bugs. We rewrote the entire transaction processing subsystem of our database to make it faster and more scalable – a bonkers thing to do btw – and the project was shockingly not a debacle, and oh yeah it had no bugs. We had built this sophisticated testing system to make our database more solid, but to our shock that wasn’t the biggest effect it had. The biggest effect was that it gave our tiny engineering team the productivity of a team 50x its size.
In 2015, Apple acquired FoundationDB and began using it as the “underpinning of their cloud infrastructure” (that’s a direct quotation from Apple, so they can’t sue me), and then open sourced it a few years later. As our team began to disperse throughout other big tech companies, we were shocked to find that even in these sophisticated organizations, nothing like FoundationDB’s deterministic simulation testing existed. The near-impossibility of anticipating unintended system impacts meant that changes to their backend systems happened at a snail’s pace, and diagnosing and fixing production bugs consumed months of extremely valuable time from some of their most senior engineers.
So I called up my friend and former boss Dave Scherer (FoundationDB’s chief architect), and told him: “There’s a $100 bill lying on the sidewalk here man.” Of course, economic theory will tell you that those don’t exist. There’s always a catch, always some horrible reason that the pot of gold is surrounded by corpses. But starting a company is about banishing that thought and telling yourself that when you reach the pit full of poisonous spikes, you’ll figure something out. So in 2018, we started Antithesis with the goal of bringing the superpower of FoundationDB-style deterministic autonomous testing to everybody else.

What we’ve built
Sure enough, the $100 bill is surrounded by an entire field of poisonous spike-pits, nay, a continent of them. Here’s an obvious one: how do you take an arbitrary piece of software, which is probably doing stuff like spawning threads, checking the time, asking the kernel for random numbers, and talking to other software over a network, and make it deterministic? At FoundationDB we had the benefit of a green-field project that we knew we wanted to test this way, and we had no dependencies (or at least, we didn’t once we’d deleted them all).
But any new software development methodology that requires everybody to rewrite everything from scratch isn’t going to get very far. We thought about this and decided to just go all out and write a hypervisor which emulates a deterministic computer. Consequently, we can force anything inside it to be deterministic. That meant learning lots of fun new things about how Intel CPUs handle extended page tables and other related horrors. It’s a story for another time, but it’s a good example of the kind of poisonous spike-pit we’ve gotten to explore (and it’s far from the worst one!).2
Anyway, we’ve built a platform that takes your software and hunts for bugs in it. When it finds one, that bug is always perfectly reproducible, no matter what crazy thing your software was doing–even if it involves multiple services communicating across a network. Also, once we’ve found a bug, we can bring some relatively space-age and insane debugging capabilities to bear on it. The platform is designed to be able to someday find many kinds of bugs in many kinds of software, but for now, we’re focused solely on distributed systems reliability / fault tolerance testing, because it’s an area where we already know what we’re doing.
Over the past several years we’ve partnered with engineering teams at a bunch of organizations with big and complicated systems whose reliability they consider critical. We’ve worked with MongoDB for several years, helping them test their core server software as well as their WiredTiger storage engine. We began working with the Ethereum Foundation about a year ahead of the Merge in order to help them test it, and continue working with them today. And we’re working with Palantir.
Initially, these customers thought of Antithesis as a “special forces” tool that primarily helped them find and replicate their most elusive and dangerous bugs. But as our platform has become more mature and interactive, we’ve shifted to being an “always on” service that continuously tests the most recent builds of their software, thus shortening the time from bug introduction to bug discovery. When building FoundationDB, we found that this made diagnosing and fixing bugs dramatically easier, increasing our efficiency and improving our software quality. Our customers are seeing this effect now, and we’re excited to help many more of you reach the ~zero bugs promised land in the years to come.
Get in touch?
If your organization runs a distributed system and values reliability and engineering productivity, we’d love to talk.
Do you occasionally walk into a spike pit and say to yourself: “Not bad, but these spikes really aren’t poisonous enough”? If so, please take a look at our open positions.
If you’ve got questions or comments, feel free to reach out on TwitterX or contact@antithesis.com (we’ll actually reply).
If you’ve made it this long – thank you for reading. More to come soon.