
An ounce of prevention is worth a pound of cure

Scene one. An engineering interview is about to end, and I’m trying to make sure that the interviewee has had the chance to ask all the questions they care about. The interviewee has one last question for me. First, they hesitate… then, the questions all come out in a torrent:
- What does your on-call load look like?
- How often do I have to be on-call?
- How often do I get called while on-call?
- Tell me more about what you do to improve the life of the on-call?
- How do you decide whether to ship the next feature or whether to invest in stability to improve the lives of those who are on-call?
These are by far the most common “work-life balance” questions that I’ve been asked across the hundreds of interviews I’ve conducted over the years. The majority of these engineers had struggled and burned out maintaining low-quality systems that were easily destabilized in production when even minimal changes rolled out. They were victims of a common mindset in our industry: As long as we can detect it and mitigate it quickly, we are good.
Scene two. During some downtime at our booth at SRECon 2024, I go around with my engineering director’s hat on to scout the products and innovations that are being showcased by the conference sponsors. I notice that the overwhelming majority of energy and innovation is going towards monitoring and detecting failures (in the form of observability tools), or towards managing failures when they happen (in the form of incident response tools). Unfortunately, there is very little innovation, attention, or energy directed towards preventing failures in the first place.
And it’s not just SRECon — a wider look at the state of software reliability engineering shows that something is off, and that most teams are investing in the mere management of failures, rather than in avoiding them in the first place.
While the business of reliability engineering has progressed quite a bit in the past decades, most of the energy has gone towards managing change, software observability, and failure management. Very little attention has been given to reducing the number of failure states produced in the first place. There are some positive trends: chaos engineering has come onto the scene, scale testing exercises have become more common, and disaster recovery has improved. But these practices are still not very widely used. And even when they are used, the scope of the situations and behaviors that are tested tends to be very limited.
Bug funnel
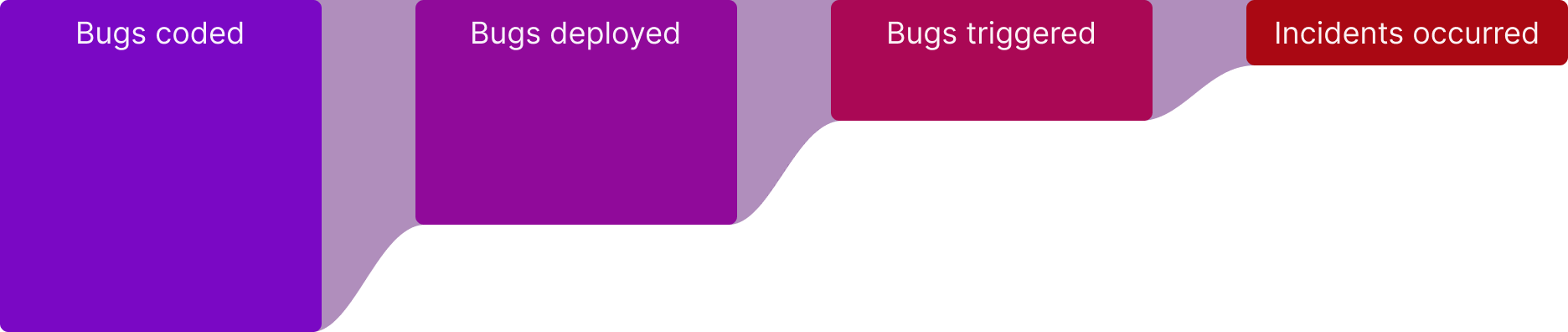
Imagine your deployment pipeline like a funnel. Occasionally, a bug (or a few bugs) make it through the funnel undetected. From a bug’s eye view, this funnel is made up of multiple stages: “bugs coded,” “bugs deployed,” “bugs triggered,” and “enough bugs triggered to cause an outage.” Like an acquisition funnel, the more that goes into the top of the funnel, the more that will come out at the end. The more bugs your engineering process produces, the more likely you are to hit an outage in production.
Practices such as unit testing, integration testing, and so on try to reduce the number of bugs passing through your funnel. But they are not good enough because they are only testing scenarios that their creators anticipated, leaving a vast number of unanticipated scenarios untested. Observability and monitoring tools try to give you insight into the bugs that make it through the funnel. Incident management practices try to help you manage the state and recovery of your system if enough bugs make it through to disrupt the normal usage of your software.
At Antithesis, we believe that with our testing technology we can transform the lives of teams by enabling them to find unanticipated bugs and unknown unknowns before they make it through the funnel.
Reducing the number of bugs making it through the funnel will result in both higher quality software and an immense increase in developer productivity, because it cuts down the costs of managing the downstream effects of these bugs. We call this the flow state for teams. Our founders have hit this flow state for teams before, as Will describes in his post:
At FoundationDB, once we hit the point of having ~zero bugs and confidence that any new ones would be found immediately, we entered into this blessed condition and we flew. Programming in this state is like living life surrounded by a force field that protects you from all harm. Suddenly, you feel like you can take risks.
How does Antithesis enable this transformation?
Antithesis has a few key features that make it easier to enter this flow state, where the quality of your software compounds on itself because your team is spending less time fighting fires.
Don’t write tests, describe behavior
When using Antithesis, instead of writing unit and integration tests that exercise the happy paths – or the unhappy paths that you can anticipate or have hit in the past – you instead describe what behavior is expected from your software. It is a lot easier to describe your API in terms of the expected inputs and expected behavior than to imagine every possible combination of inputs, states, and potential outputs. All you have to do is specify what the software should accept and how it should behave (you can even use our SDK to do that while you’re writing the code.) This delegates the hardest part of testing – imagining all the possible combinations and states your software could get into – to Antithesis.
Make your testing more hostile than production
With Antithesis you are always testing your software in an environment that is more hostile than production, rather than in a local or staging environment with low traffic. Our simulation is, by default, configured to expose your software to faults and hostilities that are usually much worse than what your software will experience in production. This not only exposes issues in your software, but hardens your engineering practices so that engineers are constantly operating with the mindset of “my software needs to work regardless of what is thrown at it” instead of operating in the happy path mindset.
Don’t just find bugs, reproduce them
Every issue that is found in Antithesis is deterministically reproducible. Thus, every time your team uncovers one of those “one-offs” or “it just happened once” or “we cannot reproduce this gnarly issue again” situations within Antithesis, instead of dismissing those issues, they can actually reproduce them over and over again to understand them, and harden your system against them with our deterministic hypervisor.
A better approach to software development
Imagine a new world where the majority of issues are found before they get deployed.

Confident delivery
Every change can be described by its author and is comprehensively validated in an environment that is more hostile than your production environment. Unlike chaos engineering, where testing your software risks causing issues in your production environment, with Antithesis you get the benefits of a hostile environment without the risks of disrupting real customers. How much more confidence will your team have while shipping new features? How many more previously risky changes can now be safely made?
Straightforward debugging
You have a catalog of every possible way your software can fail; thus, even if you do not have the time to fix certain failure modes yet, when any of those failure modes suddenly become priorities, you can instantly reproduce them deterministically for debugging and resolution. How much faster can you find root causes and fix your issues?
Peace of mind
Have you ever had an issue that caused a second outage, because the unit or integration test added to prevent it only tested one way the bug could manifest? If you describe what a failure looks like to Antithesis, then it will continuously check each new build for this faulty state – not only with the known inputs, but in a large set of possible situations. Imagine having the peace of mind that a problem will truly never happen again, allowing you to avoid adding new metrics, alerts, and dashboards for every class of issue you uncover in production. How much simpler and more efficient will your observability practices be?
Stop treading water. Start swimming.
Engineering teams have multiple equilbria, and it’s easy to get stuck in the one where so much effort is getting poured into managing failures, you barely have time to do anything else. This is why the metaphor of technical debt is so powerful — it really does act like a high-interest credit card where if you’re not careful, you end up paying so much for your previous decisions that there’s no way for you to escape the trap.
The good news is that it is possible to move from this equilibrium to the flow-state one. The key is detecting bugs early, before they cause problems, when they’re cheaper to solve. We’ve seen multiple teams make this transition. They start by setting things up so that new bugs are caught quickly and don’t produce big outages, then they have breathing room to dig out of the backlog of historical bugs in a methodical way. It’s never too late! If you want help with this, if you want your pager to stop ringing every week, then contact us and we will help!