Sizing your Antithesis deployment
Every year, computing power gets cheaper (while engineering labor gets more expensive), but conventional testing hardly benefits from this. With conventional testing, running a test twice on the exact same code does not produce any additional value. The test either found the bug in the first place or it never will; further test runs will not add any information. With autonomous testing, the situation is very different – running the test a second time will generate a second scenario with different inputs and different events, potentially triggering very different codepaths in your system and uncovering some unexpected or buggy behavior. Autonomous testing can take advantage of cheap compute, but this raises a new question: how many times should we run these tests?
Antithesis operates continuously, immediately running a test again as soon as the previous run has finished. The parameter that you can control is parallelism – how many such runs are happening simultaneously. More parallelism means that we are able to find bugs faster. Suppose that there is a rare but catastrophic bug which on average can be found by a single CPU core after 1,000 hours of testing. If we instead task two CPU cores with the testing, then on average they will find the bug after just 500 hours. The improvement is roughly linear, because autonomous testing is an embarassingly parallel problem.
So the question: “how should I size Antithesis?” is really just the question: “how fast do I want to find bugs after they’re introduced?” The answer to this question is different for every organization, but we think finding bugs fast will save you time and money in the long run. Although the time to find a bug decreases linearly with the number of cores, the benefit to finding bugs faster is drastically better than linear. The reason is that finding a bug can be thought of as a race, or more precisely as two distinct races.
The race against customers
Suppose that a critical bug is hiding in a release of your software. There’s some average time for tests to find this bug. But you are not the only one testing your code – every day, your customers are using your code; after a certain number of customer “test hours”, they are likely (on average) to find it. And they are probably doing a lot more cumulative testing than you did! Someone will find it first, you or them.
So the race is on. You want to win this race, because it is cheaper to find bugs yourself before your customers find them. Bugs in production will harm your reputation and make your customers unhappy. In the worst case, they can result in outages or data breaches that result in negative publicity and contractual liability. It is very difficult to judge the quality of an underlying codebase and customers reasonably treat individual bugs as symptomatic of larger issues.
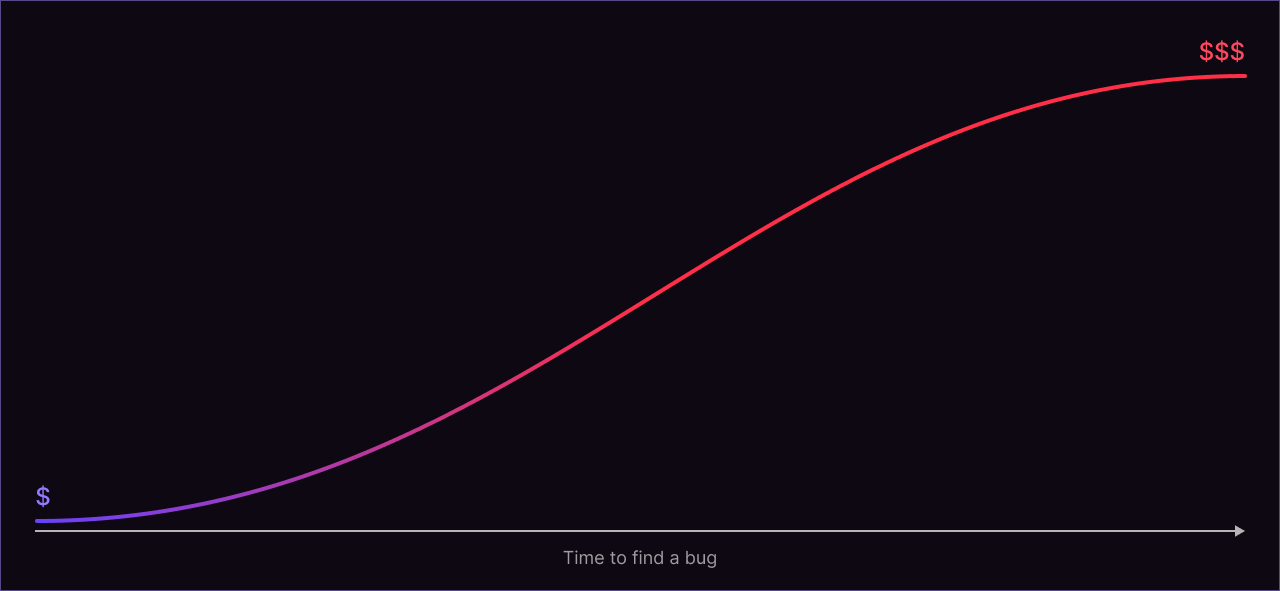
Bugs discovered in production are also expensive to fix, because customers are less able to accurately and completely describe the issue they have encountered. Not only are the bug reports less informative, but you will often lack important diagnostic information or logs that you would have if the bug were found in a controlled setting. Moreover, you may need to do an emergency hotfix or workaround for customer satisfaction reasons in parallel with solving the underlying issue. This can carry its own risks, and can result in duplication of engineering effort. These are just some of the indirect costs of losing the bug-finding race with your customers.
You likely have many more customers than testers, so how can you hope to reliably win this race? Through taking advantage of parallelism – with more autonomous tests run in parallel, you can expand the size of your virtual testing team using cheap compute rather than expensive labor. Better still, Antithesis’s tests are of much higher quality than customer tests: most customers will use software in a fairly basic way, whereas Antithesis is using its time more efficiently through techniques such as fault injection, coverage guidance, and randomized test templates. Using the metaphor of a race, think of the time for one core to find a bug as the distance you have to run, and computational parallelism as your speed. The Antithesis platform helps shorten the distance using these techniques, and helps you go faster with parallelism. You want to go fast enough that you are always or almost always winning the race against your customers. But the race against your customers is not the only race.
The race against yourself
Consider a situation where an engineer writes some buggy code, runs a test, and immediately encounters a new failure. The path to resolving that issue is very direct – the engineer simply reverts the change that they just made, and thinks a little bit harder about how to do it correctly. Time cost of the bug: almost zero.
Now consider a situation where an engineer writes some buggy code, runs a test, the test passes, and the code is accepted into a new release. Months later, the bug manifests in some different test or in production. The cost of resolving this bug could be huge, potentially so huge that it’s not even worth trying to fix! Rather than just reverting some recently modified code, your team now needs to do an extensive root-cause analysis to troubleshoot the issue. Once the underlying problem is found, it will still be expensive to fix. The team may have forgotten the details of why the change was made, and what the mental model was that led to it. Even worse, the engineers involved may have switched teams, gotten promotions, changed jobs, or retired. Either way, a vast amount of contextual knowledge associated with the bug has been lost, and will need to be painfully relearned in order to resolve the issue.
Even if your customers aren’t the ones finding it, it’s much cheaper to solve a bug when you find it quickly. This is the race against yourself.
Optimal usage
Let’s return to our original question: “how should I size Antithesis?” The short answer is, with enough parallelism to ensure that you are regularly winning both the race against your customers and the race against yourself. Every organization is different – different numbers of customers, different release cycles, different quality goals, different engineering practices, not to mention different software! So there’s really no one-size fits all answer to this question, instead we recommend taking an empirical approach.
If you do a proof-of-concept with us, by the end of it we should have enough data about real-world bugs to make a recommendation. If you instead decide to jump straight in with Antithesis, feel free to start small with a single 48-core instance and then continuously re-evaluate as you get more data about whether you’re winning these two races.
If a bug is found in production, or by your customers, you should demand an explanation from us. It could be that your Antithesis setup is misconfigured, such that the circumstances leading up to the bug can never occur. Or it could be that there’s a limitation in your test template that means the bug will never or almost never be seen. But there’s also a chance that the answer is simply that you aren’t running your tests with enough parallelism, so we would have found it eventually, we just didn’t find it in time. When this happens, it’s a pretty good indication that you should be testing more.
If a bug is found in your Antithesis tests one night, is it found every time thereafter? If not, you should demand an explanation from us. A bug that is found occasionally or unreliably is like a flashing red warning indicator that your tests are not powerful enough. Again, the reason could be misconfiguration, a weak workload, or not enough parallelism. It’s very important to find out which one is happening, because they suggest different solutions.
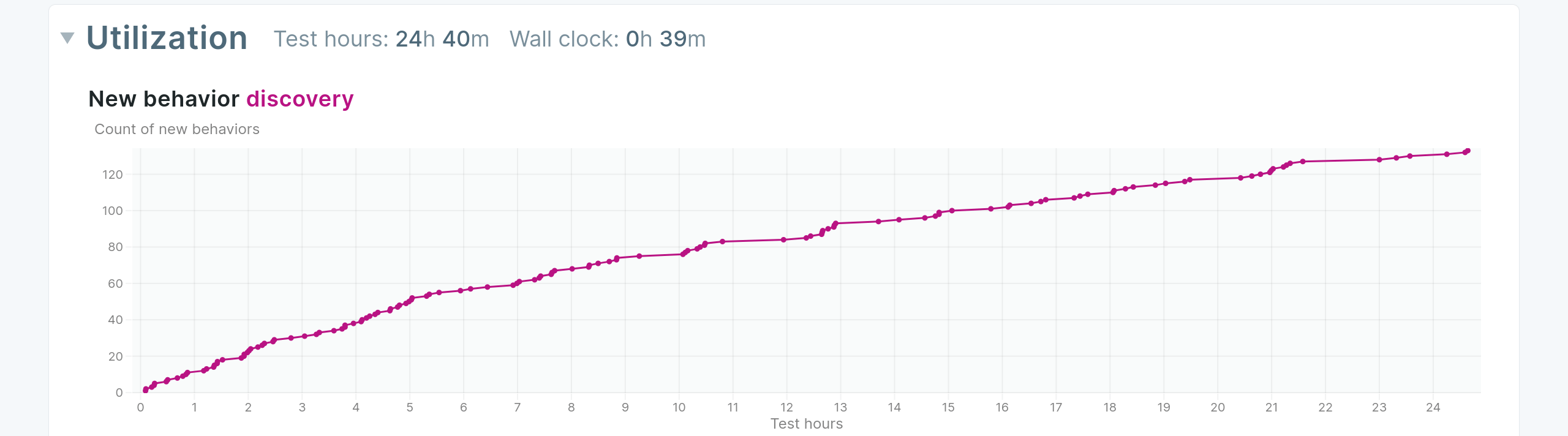
Antithesis provides a tool to help diagnose misconfiguration and workload problems. The triage reports you receive contain a graph in the “Utilization” section which plots new behaviors discovered over the duration of a single test. It’s in the nature of autonomous testing for there to be diminishing returns with each new test, so it’s normal for this graph to look roughly logarithmic. However if the graph hits a hard horizontal asymptote, that’s a sign that something is wrong. It means that additional test cases aren’t provoking any new behavior or code paths in your software, which is often a sign that something is misconfigured, or that your workload isn’t varied enough. In any case, more testing will not help find more bugs in this situation.
We can also come from the other direction, and do an analysis to see whether increasing the parallelism would result in bugs being found faster. For any particular issue that you think is representative of the bugs you’re facing, feel free to ask us to estimate how quickly it would have been found if you had been running with either more or less parallelism. If we’ve found the bug on multiple independent occasions, we can probably give you a very accurate answer to this question, and it can be a big help when evaluating what level of parallelism you wish to purchase.
We can also “burst” your level of testing for a short duration, and see whether that results in finding more issues than we were before. If running at a higher usage rate turns up more issues than you’re accustomed to, it’s a good sign that you’re leaving value (and bugs) on the table.
If your software is exceptionally well-tested and bugs are rare, you can perform all of the above analyses with artificial bugs that you deliberately introduce into your builds, or with Sometimes Assertions for situations that you know are rare but important. Whichever way you do it, this is an important discipline to get into, because the question we all want to know the answer to is: “how many more bugs are out there?” While it’s impossible to ever know for sure, artificial bugs and Sometimes Assertions can give you a lot of confidence in either direction. If we find them quickly and reliably, we’re probably also finding your bugs quickly and reliably. If not, you should consider beefing up your workload or increasing your parallelism.